
Diagnosing Planning Quality in LLM-Based Penetration Testing Using Execution-Free Evaluation
DOI:
https://doi.org/10.66279/enzxq198Keywords:
Cybersecurity, Penetration Testing, Tool-Use Planning, Security Evaluation, LLM AgentsAbstract
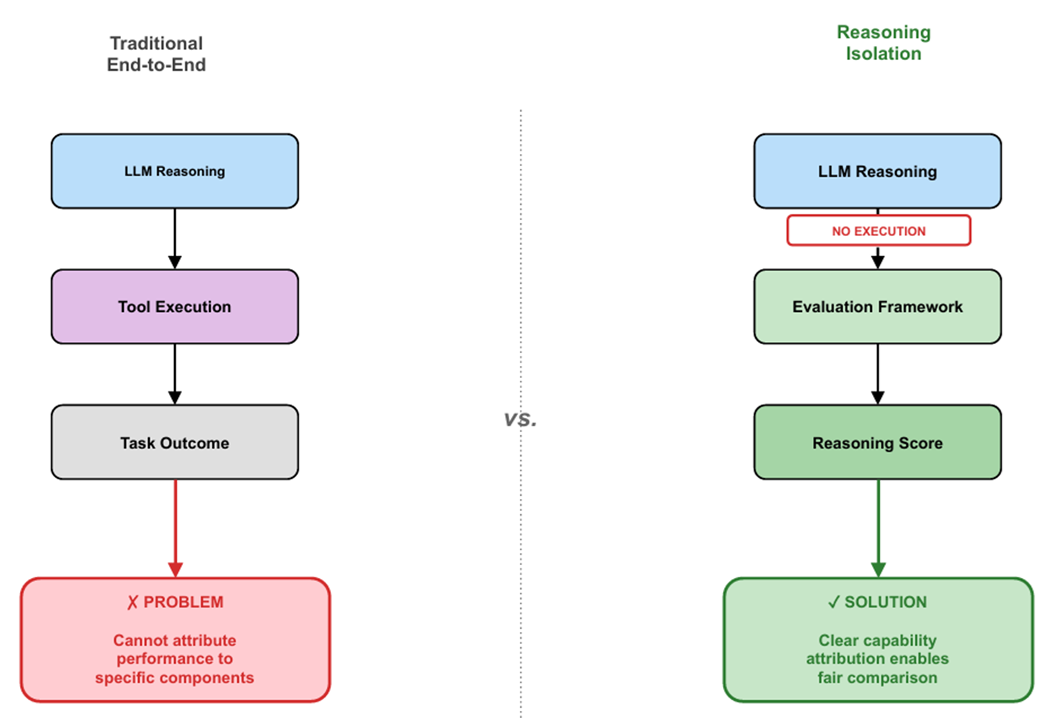
Evaluating language model (LLM) penetration testing agents through execution conflates planning quality with environmental factors, including network latency, tool failures, and infrastructure variability. Analysis of AutoPenBench logs reveals that 40\% of agent failures arise from environmental timeouts rather than planning errors, obscuring the true diagnostic signal. We present an \textit{execution-free}, rubric-based evaluation framework that directly assesses the quality of LLM-generated attack plans along five independently scored dimensions: tool relevance, sequence logic, completeness, efficiency, and reasoning quality. Ten penetration testing scenarios spanning reconnaissance to post-exploitation are stratified by difficulty and evaluated across four models: GPT-4o, GPT-4o-mini, Llama-3.3-70B, and Qwen-2.5-14B—using automated scoring via Claude Sonnet 4.5 at temperature=0. Model scores range from 58\% to 74\%, substantially above the random baseline of 18\% but below the 96\% achieved by expert-generated reference plans, confirming a 78-percentage-point discriminative range. Dimension-level analysis reveals balanced performance across rubric criteria (means 7.0–7.3/10) with notable inter-model variation in efficiency (6.0–7.6) and reasoning quality (5.8–8.1). To strengthen validity, we discuss requirements for human expert validation and inter-rater reliability (target Krippendorff's $\alpha \geq 0.67$), multi-sample generation for variance estimation, and the inclusion of evasion and obfuscation scenarios. The framework offers a reproducible, infrastructure-independent diagnostic tool for model development and security education, intended to complement—not replace—execution-based benchmarks.
Downloads
References
1] L. Gioacchini, M. Mellia, I. Drago, A. Delsanto, G. Siracusano, and R. Bifulco, “Autopenbench: Benchmarking generative agents for penetration testing,” arXiv preprint arXiv:2410.03225, 2024.
[2] M. Shao, S. Jancheska, M. Udeshi, B. Dolan-Gavitt, H. Xi, K. Milner, B. Chen, M. Yin, S. Garg, P. Krishnamurthy, et al., “Nyu ctf bench: A scalable open-source benchmark dataset for evaluating llms in offensive security,” Advances in Neural Information Processing Systems, vol. 37, pp. 57472–57498, 2024.
[3] Y. Wu, F. Roesner, T. Kohno, N. Zhang, and U. Iqbal, “Isolategpt: An execution isolation architecture for llm-based agentic systems,” arXiv preprint, arXiv:2403.04960, 2024.
[4] J. Yang, A. Prabhakar, K. Narasimhan, and S. Yao, “Intercode: Standardizing and benchmarking interactive coding with execution feedback,” Advances in Neural Information Processing Systems, vol. 36, pp. 23826–23854, 2023.
[5] Y. Ruan, H. Dong, A. Wang, S. Pitis, Y. Zhou, J. Ba, Y. Dubois, C. J. Maddison, and T. Hashimoto, “Identifying the risks of lm agents with an lm-emulated sandbox,” arXiv preprint arXiv:2309.15817, 2023.
[6] PTES Technical Guidelines Working Group, “Penetration testing execution standard – technical guidelines,” 2014. Accessed: 2025-04-24.
[7] G. Deng, Y. Liu, V. Mayoral-Vilches, P. Liu, Y. Li, Y. Xu, T. Zhang, Y. Liu, M. Pinzger, and S. Rass, “Pentestgpt: An llm-empowered automatic penetration testing tool,” arXiv preprint arXiv:2308.06782, 2023.
[8] S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” Advances in neural information processing systems, vol. 36, pp. 11809–11822, 2023.
[9] D. Pratama, N. Suryanto, A. A. Adiputra, T.-T.-H. Le, A. Y. Kadiptya, M. Iqbal, and H. Kim, “Cipher: Cybersecurity intelligent penetration-testing helper for ethical researcher,” Sensors, vol. 24, no. 21, pp. 6878, 2024.
[10] A. Happe and J. Cito, “Getting pwn’d by ai: Penetration testing with large language models,” in Proceedings of the 31st ACM joint european software engineering conference and symposium on the foundations of software engineering, pp. 2082–2086, 2023.
[11] Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, et al., “Toolllm: Facilitating large language models to master 16000+ real-world apis,” arXiv preprint arXiv:2307.16789, 2023.
[12] Z. Chen, W. Du, W. Zhang, K. Liu, J. Liu, M. Zheng, J. Zhuo, S. Zhang, D. Lin, K. Chen, et al., “T-eval: Evaluating the tool utilization capability of large language models step by step,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol. 1: Long Papers), pp. 9510–9529, 2024.
[13] X. Wang, Z. Wang, J. Liu, Y. Chen, L. Yuan, H. Peng, and H. Ji, “Mint: Evaluating llms in multi-turn interaction with tools and language feedback,” arXiv preprint arXiv:2309.10691, 2023.
[14] H. P. T. Nguyen, K. Hasegawa, K. Fukushima, and R. Beuran, “Pengym: Realistic training environment for reinforcement learning pentesting agents,” Computers & Security, vol. 148, pp. 104140, 2025.
[15] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” Advances in neural information processing systems, vol. 36, pp. 46595–46623, 2023.
[16] Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: Nlg evaluation using gpt-4 with better human alignment,” in Proceedings of the 2023 conference on empirical methods in natural language processing, pp. 2511–2522, 2023.
[17] Y. Dubois, B. Galambosi, P. Liang, and T. B. Hashimoto, “Length-controlled alpacaeval: A simple way to debias automatic evaluators,” arXiv preprint arXiv:2404.04475, 2024.
[18] A. Panickssery, S. R. Bowman, and S. Feng, “Llm evaluators recognize and favor their own generations,” Advances in Neural Information Processing Systems, vol. 37, pp. 68772–68802, 2024.
[19] P. Wang, L. Li, L. Chen, Z. Cai, D. Zhu, B. Lin, Y. Cao, L. Kong, Q. Liu, T. Liu, et al., “Large language models are not fair evaluators,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 9440–9450, 2024.
[20] Kali Linux, “Kali linux tools listing.” Kali Linux Documentation, 2024. Accessed: 2025-04-24.
[21] L. Crocker and J. Algina, Introduction to classical and modern test theory. ERIC, 1986.
[22] C. H. Lawshe, “A quantitative approach to content validity,” Personnel psychology, vol. 28, no. 4, pp. 563, 1975.
[23] K. Krippendorff, “Computing krippendorff’s alpha reliability. departmental papers (asc) 43,” 2011.
[24] K. A. Hallgren, “Computing inter-rater reliability for observational data: an overview and tutorial,” Tutorials in quantitative methods for psychology, vol. 8, no. 1, pp. 23, 2012.
Downloads
Published
Data Availability Statement
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
Issue
Section
Categories
License
Copyright (c) 2026 Journal of Smart Algorithms and Applications (JSAA)

This work is licensed under a Creative Commons Attribution 4.0 International License.
Journal of Smart Algorithms and Applications (JSAA) content is published under a Creative Commons Attribution License (CCBY). This means that content is freely available to all readers upon publication, and content is published as soon as production is complete.
Journal of Smart Algorithms and Applications (JSAA) seeks to publish the most influential papers that will significantly advance scientific understanding. Selected articles must present new and widely significant data, syntheses, or concepts. They should merit recognition by the wider scientific community and the general public through publication in a reputable scientific journal.










