
Unified Hybrid Self-Supervised Architecture Combining Contrastive and Non-Contrastive Learning for Multi-Level Visual Representation
Keywords:
Contrastive learning, Representation learning, Non-contrastive learning, Unlabeled image datasetsAbstract
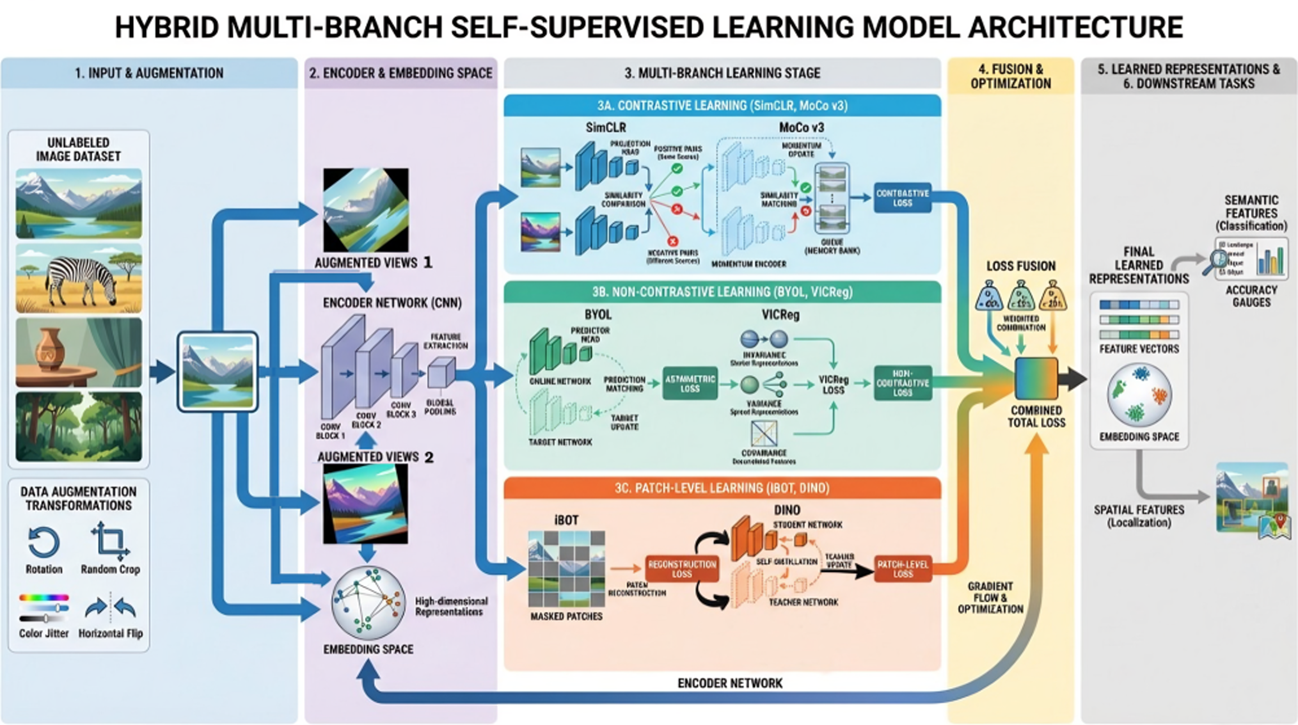
This paper presents a hybrid self-supervised learning framework for fine-grained visual representation using the STL-10 dataset. Addressing the challenges of limited labeled data and complex image variations, the proposed approach integrates four self-supervised paradigms, BYOL, SimCLR, MoCo v3, and DINO into a unified architecture. The model uses a shared backbone with projection and predictor heads, along with a target network updated via an exponential moving average (EMA), to extract robust representations from unlabeled images. Data augmentations, including random resized cropping (RRC), horizontal flipping, color jittering, and grayscale conversion, are employed to generate multiple correlated views for combined contrastive and non-contrastive learning. Experimental results demonstrate stable convergence with an average BYOL loss of –0.88. Downstream evaluation confirms the high quality of the learned embeddings, achieving a test accuracy of (87.20%), a recall of (87.20%), and an F1 score of (87.19%). Furthermore, the framework attained a mean Average Precision (mAP) of (93.70%), indicating highly discriminative and transferable feature representations. We demonstrate that hybrid self-supervision effectively leverages mutually complementary learning paradigms, yielding superior representation quality and faster convergence compared to single-method baselines.
Downloads
References
[1] T. Uelwer, J. Robine, S.S. Wagner, et al., A survey on self-supervised methods for visual representation learning, Mach. Learn. 114 (2025) 111.
[2] W. Qin, Y. Li, J. Zhang, X. Wen, J. Guo, Q. Guo, Attention-based hybrid contrastive learning for unsupervised person re-identification, Sci. Rep. 15(1) (2025) 13238.
[3] M. Kang, J. Kim, Enhancing self-supervised visual representation learning through adversarially generated examples, Neural Comput. & Applic. 37 (2025) 14613–14634.
[4] J. Nadine, Self-supervised learning principles challenges and emerging directions, Preprints (2025) 2025021894.
[5] F. Sun, J. Liu, J. Wu, C. Pei, X. Lin, W. Ou, P. Jiang, BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer, Proc. 28th ACM Int. Conf. Inf. Knowl. Manag. (2019) 1441–1450.
[6] S. Zhao, L. Zhu, X. Wang, et al., Slimmable networks for contrastive self-supervised learning, Int. J. Comput. Vis. 133 (2025) 1222–1237.
[7] T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, arXiv preprint arXiv:2002.05709 (2020).
[8] X. Chen, S. Xie, K. He, An empirical study of training self-supervised vision transformers, arXiv preprint arXiv:2104.02057 (2021).
[9] T. Chen, S. Kornblith, K. Swersky, M. Norouzi, G. Hinton, Big self-supervised models are strong semi-supervised learners, arXiv preprint arXiv:2006.10029 (2020).
[10] V.K. Reja, S. Goyal, K. Varghese, B. Ravindran, Q.P. Ha, Hybrid self-supervised learning-based architecture for construction progress monitoring, Autom. Constr. 153 (2023) 105225.
[11] A. Khan, S. AlBarri, M.A. Manzoor, Contrastive self-supervised learning: A survey on different architectures, Proc. 2nd Int. Conf. Artif. Intell. (2022) 1–6.
[12] G. Nagaraj, M.N. Rao, J.P. Wankhede, S.G. Rao, H.M. Abas, N. Gireesh, Self-supervised feature learning for robust image understanding in noisy and unstructured data, Proc. Int. Conf. Metaverse Curr. Trends Comput. (2025) 1-4.
[13] L. Shang, T. Wang, L. Gong, C. Wang, X. Zhou, Enhancing HLS performance prediction on FPGAs through multimodal representation learning, IEEE Embed. Syst. Lett. 16(4) (2024) 385-388.
[14] R.A. Jarvis, A perspective on range finding techniques for computer vision, IEEE Trans. Pattern Anal. Mach. Intell. 5(2) (1983) 122–139.
[15] I. Misra, L. van der Maaten, Self-supervised learning of pretext-invariant representations, Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (2020) 6707-6717.
[16] T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, Proc. Int. Conf. Mach. Learn. 119 (2020) 1597-1607.
[17] X. Chen, S. Xie, K. He, An empirical study of training self-supervised vision transformers, Proc. IEEE/CVF Int. Conf. Comput. Vis. (2021) 9640-9649.
[18] J.B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, et al., Bootstrap your own latent: A new approach to self-supervised learning, Adv. Neural Inf. Process. Syst. 33 (2020) 21271-21284.
[19] A. Bardes, J. Ponce, Y. LeCun, VICReg: Variance-invariance-covariance regularization for self-supervised learning, Proc. Int. Conf. Learn. Represent. (2022).
[20] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, et al., Emerging properties in self-supervised vision transformers, Proc. IEEE/CVF Int. Conf. Comput. Vis. (2021) 9650-9660.
[21] J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, et al., iBOT: Image BERT pre-training with online tokenizer, Proc. Int. Conf. Learn. Represent. (2022).
[22] A. van den Oord, Y. Li, O. Vinyals, Representation learning with contrastive predictive coding, arXiv preprint arXiv:1807.03748 (2018).
[23] I. Loshchilov, F. Hutter, Decoupled weight decay regularization, Proc. Int. Conf. Learn. Represent. (2019).
[24] T. Wang, P. Isola, Understanding contrastive representation learning through alignment and uniformity on the hypersphere, Proc. Int. Conf. Mach. Learn. 119 (2020) 9929-9939.
[25] K. He, H. Fan, Y. Wu, S. Xie, R. Girshick, Momentum contrast for unsupervised visual representation learning, Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (2020) 9729-9738.
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2026 Journal of Smart Algorithms and Applications (JSAA)

This work is licensed under a Creative Commons Attribution 4.0 International License.
Journal of Smart Algorithms and Applications (JSAA) content is published under a Creative Commons Attribution License (CCBY). This means that content is freely available to all readers upon publication, and content is published as soon as production is complete.
Journal of Smart Algorithms and Applications (JSAA) seeks to publish the most influential papers that will significantly advance scientific understanding. Selected articles must present new and widely significant data, syntheses, or concepts. They should merit recognition by the wider scientific community and the general public through publication in a reputable scientific journal.










