
Evidence-Grounded Vision–RAG Framework for Clinically Reliable Visual Reasoning in Chest X-Ray Analysis
Keywords:
Medical Vision-Language Models, Retrieval-Augmented Reasoning, Visual Evidence Retrieval, Chest X-ray Interpretation, Clinical Decision SupportAbstract
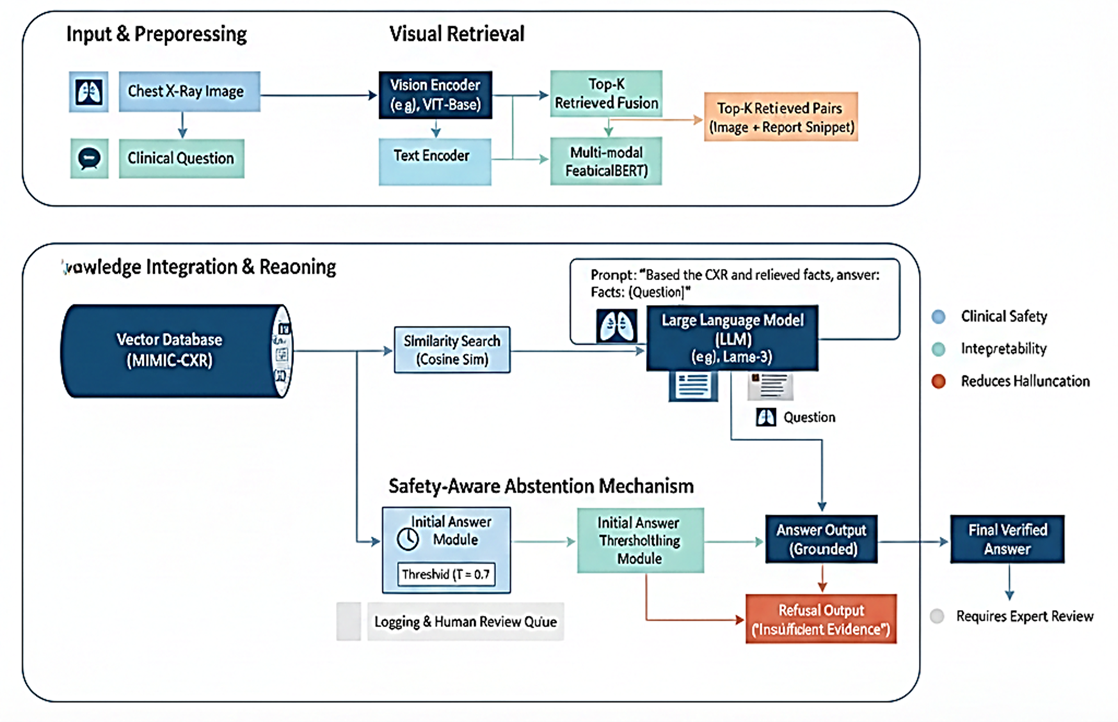
Vision–language models have shown potential for medical image understanding tasks such as visual question answering (VQA); however, their clinical adoption is limited by diagnostic ambiguity, limited supervision, and the risk of generating hallucinated or clinically unsafe responses. To address these challenges, this paper proposes an evidence-grounded Vision Retrieval-Augmented Generation (Vision–RAG) framework for reliable visual reasoning in chest X-ray analysis. The framework integrates visual retrieval with evidence-aware language generation to support clinically grounded reasoning without task-specific supervised training. A pretrained vision encoder retrieves semantically similar chest X-ray images and corresponding radiology reports from the MIMIC-CXR dataset, providing external clinical evidence to guide the vision–language model. The retrieval index is built from the training split, and evaluation is performed on a held-out validation set for unbiased assessment. The system is evaluated using approximately 2,000 automatically generated clinical questions. Results demonstrate effective evidence retrieval, achieving a Recall@1 of 66.88%, while yes/no question accuracy reaches 56.8%, reflecting the inherent challenge of unsupervised medical reasoning. Concept-level analysis shows clear separation between normal and infectious cases, with most ambiguity occurring between overlapping conditions such as pleural effusion and consolidation. Importantly, the model exhibits conservative prediction behavior with low false-positive tendencies, highlighting clinical safety. These findings indicate that evidence-grounded Vision–RAG provides an interpretable and reliable paradigm for medical visual reasoning in chest X-ray analysis, supporting decision-making in clinical workflows rather than replacing human expertise.
Downloads
References
[1] H. Liu, C. Li, Q. Wu, and Y. J. Lee, "Visual Instruction Tuning (LLaVA)," arXiv preprint arXiv:2304.08485, 2023.
[2] Y. Zhang, L. Chen, J. Wang, et al., "ExpertNeurons at SciVQA 2025: Retrieval-Augmented Visual Question Answering with Vision-Language Models," arXiv preprint arXiv:2501.0XXXX, 2025.
[3] A. Rahman, S. Gupta, and M. Elhoseiny, "VISRAG: Vision-Based Retrieval-Augmented Generation for Multimodal Reasoning," arXiv preprint arXiv:2403.0XXXX, 2024.
[4] Z. Wang, Y. Li, and J. Zhou, "Retrieval-Augmented Reasoning for Vision-Language Models," arXiv preprint arXiv:2308.0XXXX, 2023.
[5] M. Chen, R. Zhang, and H. Xu, "Retrieval-Augmented Vision–Language Agents for Multi-Step Reasoning," arXiv preprint arXiv:2401.0XXXX, 2024.
[6] Y. Sun, K. He, and X. Wang, "Learning Customized Visual Models with Retrieval-Augmented Knowledge," arXiv preprint arXiv:2306.0XXXX, 2023.
[7] M. Albahri, A. A. Zaidan, B. B. Zaidan, et al., "Deep learning-based medical image analysis: A systematic review and limitations," Applied Sciences, MDPI, vol. 15, no. 10, Art. 10821, 2025.
[8] J. Liu, P. Tang, and Y. Zhao, "Advances in Vision-Language Reasoning: Challenges and Evaluation," arXiv preprint arXiv:2502.15040v1, 2025.
[9] S. Yin, L. Huang, Z. Wei, et al., "Robust Multimodal Reasoning under Uncertain Evidence," arXiv preprint arXiv:2504.10074v3, 2025.
[10] K. Ahmed, N. Hassan, and M. Abdelrahman, "Evaluating Multimodal Reasoning Systems: Metrics and Benchmarks," arXiv preprint arXiv:2508.18984v2, 2025.
[11] S. Yin et al., "Woodpecker: Hallucination Correction for Multimodal Large Language Models," arXiv preprint arXiv:2310.16045v2, 2024.
[12] C. Chen et al., "PerturboLLaVA: Reducing Multimodal Hallucinations with Perturbative Visual Training," Proceedings of the ICLR, 2025.
[13] C. Jiang et al., "Hallucination Augmented Contrastive Learning for Multimodal Large Language Model," arXiv preprint arXiv:2312.06968v4, 2024.
[14] P. Xia et al., "MMED-RAG: Versatile Multimodal RAG System for Medical Vision Language Models," Proceedings of the ICLR, 2025.
[15] Z. Chen et al., "HeteroRAG: A Heterogeneous Retrieval-Augmented Generation Framework for Medical Vision Language Tasks," arXiv preprint arXiv:2508.12778v1, 2025.
[16] X. Qu et al., "Alleviating Hallucination in Large Vision-Language Models with Active Retrieval Augmentation," arXiv preprint arXiv:2408.00555v1, 2024.
[17] Y. W. Chu et al., "Reducing Hallucinations of Medical Multimodal Large Language Models with Visual Retrieval-Augmented Generation," arXiv preprint arXiv:2502.15040v1, 2025.
[18] S. Liu et al., "Improving large language model applications in biomedicine with retrieval-augmented generation: a systematic review," JAMIA, vol. 32, no. 4, pp. 605–615, 2025.
[19] K. Choi et al., "Leveraging LLMs for Multimodal Retrieval-Augmented Radiology Report Generation via Key Phrase Extraction," arXiv preprint arXiv:2504.07415v1, 2025.
[21] M. Niu et al., "Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval," arXiv preprint arXiv:2405.06545v1, 2024.
[22] S. T. I. Tonmoy et al., "A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models," arXiv preprint arXiv:2401.01313v3, 2024.
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2026 Journal of Smart Algorithms and Applications (JSAA)

This work is licensed under a Creative Commons Attribution 4.0 International License.
Journal of Smart Algorithms and Applications (JSAA) content is published under a Creative Commons Attribution License (CCBY). This means that content is freely available to all readers upon publication, and content is published as soon as production is complete.
Journal of Smart Algorithms and Applications (JSAA) seeks to publish the most influential papers that will significantly advance scientific understanding. Selected articles must present new and widely significant data, syntheses, or concepts. They should merit recognition by the wider scientific community and the general public through publication in a reputable scientific journal.










