
A Robust Two-Stage Retrieval-Augmented Vision-Language Framework for Knowledge-Intensive Multimodal Reasoning and Alignment
DOI:
https://doi.org/10.66279/2da0zk02Keywords:
Vision Language Models (VLMs), Retrieval Augmented Generation (RAG), Multimodal Reasoning Knowledge, Intensive TasksAbstract
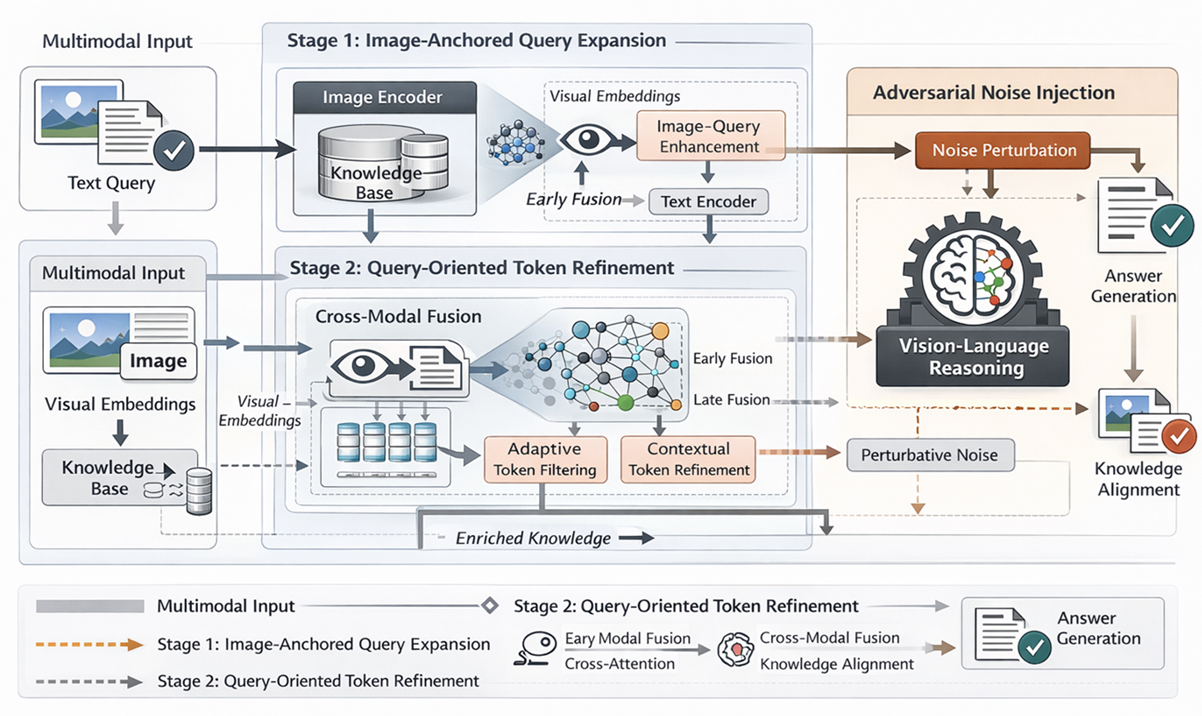
Vision-Language Models (VLMs) have demonstrated significant potential in visual perception and linguistic understanding. However, they often struggle with knowledge-intensive tasks that require linking visual scenes to external background knowledge. To address these limitations, this paper proposes the RoRA-VLM (Robust Retrieval-Augmented Vision Language Model) framework. RoRA-VLM introduces a novel two-stage retrieval mechanism—Image-anchored Textual-query Expansion—to bridge the modality discrepancy between visual and textual inputs. Furthermore, it incorporates a Query-oriented Visual Token Refinement strategy for better alignment and Adversarial Noise Injection to enhance reasoning robustness against irrelevant retrieved information. Experimental results on the InfoSeek and OVEN datasets demonstrate that RoRA-VLM significantly outperforms baseline models, achieving a 62.5% accuracy on InfoSeek, which represents a 17.3% improvement over the base LLaVA-v1.5 model. These findings highlight the effectiveness of the proposed alignment and reasoning mechanisms in developing more intelligent and robust vision-language systems.
Downloads
References
[1] J. Qi, Z. Xu, R. Shao, et al., "RoRA-VLM: Robust Retrieval-Augmented Vision Language Models," arXiv preprint arXiv:2410.08876, 2024.
[2] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun and H. Wang, “Retrieval Augmented Generation for Large Language Models: A Survey,” arXiv preprint arXiv:2312.10997, 2023.
[3] H. Liu, C. Li, Q. Wu, and Y. Li, "Improved Baselines with Visual Instruction Tuning (LLaVA-1.5)," arXiv preprint arXiv:2310.03744, 2023.
[4] M. M. Abootorabi, A. Zobeiri, M. Dehghani, M. Mohammadkhani, B. Mohammadi, O. Ghahroodi, M. S. Baghshah and E. Asgari, “Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval Augmented Generation,” Findings of the Association for Computational Linguistics: ACL 2025, pp. 16776–16809, 2025. DOI: https://doi.org/10.18653/v1/2025.findings-acl.861
[5] Q. Zhang, et al., "Beyond Text-Visual Attention: Exploiting Visual Cues for Effective Token Pruning in VLMs," in Proc. ICCV, 2025.
[6] K. Cain, et al., "FlashVLM: Text-Guided Visual Token Selection for Large Vision-Language Models," arXiv preprint arXiv:2512.20561, 2025.
[7] X. Zheng, et al., "Retrieval augmented generation and understanding in vision: A survey and new outlook," arXiv preprint arXiv:2503.18016, 2025.
[8] V.N. Rao, S. Choudhary, A. Deshpande, et al., "RAVEN: Multitask Retrieval Augmented Vision-Language Learning," arXiv preprint arXiv:2406.19150, 2024.
[9] S. Sharifymoghaddam, et al., "UniRAG: Universal retrieval augmentation for large vision language models," in Proc. NAACL, 2025. DOI: https://doi.org/10.18653/v1/2025.findings-naacl.108
[10] Y. Ming and Y. Li, "Understanding retrieval-augmented task adaptation for vision-language models," in Proc. 41st Int. Conf. Machine Learning (ICML), PMLR 235, pp. 35719–35743, 2024.
[11] Z. Yang, W. Ping, Z. Liu, et al., "Re-ViLM: Retrieval-Augmented Visual Language Model for Zero and Few-Shot Image Captioning," Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 11844–11857, 2023. DOI: https://doi.org/10.18653/v1/2023.findings-emnlp.793
[12] S. Zhao, X. Wang, L. Zhu, and Y. Yang, "Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models," in Proc. 12th Int. Conf. Learning Representations (ICLR), 2024.
[13] X. Zheng, et al., "Multimodal Iterative RAG for Knowledge-Intensive Visual Question Answering," arXiv preprint arXiv:2509.00798, 2025.
[14] M. Yasunaga, A. Aghajanyan, W. Shi, R. James, J. Leskovec, P. Liang, M. Lewis, L. Zettlemoyer, and W. Yih, "Retrieval-Augmented Multimodal Language Modeling," in Proc. ICML, PMLR 202, pp. 39755–39769, 2023.
[15] J. Zhang, M. Liu, L. Li, M. Lu, Y. Zhang, J. Pan, Q. She, and S. Zhang, "Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs," arXiv preprint arXiv:2506.10967, 2025.
[16] Q. Cao, B. Paranjape, and H. Hajishirzi, "PuMer: Pruning and merging tokens for efficient vision language models," in Proc. 61st Annu. Meeting of the ACL, pp. 12890–12903, 2023. DOI: https://doi.org/10.18653/v1/2023.acl-long.721
[17] W. Rahman, M. K. Hasan, S. Lee, A. Bagher Zadeh, C. Mao, L.-P. Morency, and E. Hoque, “Integrating multimodal information in large pretrained transformers,” in Proc. 58th Annual Meeting of the Assoc. for Computational Linguistics (ACL), Online, Jul. 2020, pp. 2359–2369. DOI: https://doi.org/10.18653/v1/2020.acl-main.214
[18] Y. Huang and J. Huang, “A Survey on Retrieval Augmented Text Generation for Large Language Models,” arXiv preprint arXiv:2404.10981, 2024.
[19] J. Lee, Y. Wang, J. Li, and M. Zhang, "Multimodal reasoning with multimodal knowledge graph (MR MKG)," arXiv preprint arXiv:2406.02030, 2024. DOI: https://doi.org/10.18653/v1/2024.acl-long.579
[20] M. Suri, P. Mathur, F. Dernoncourt, R.A. Rossi, and D. anocha, "VisDoM: Multi Document QA with Visually Rich Elements Using Multimodal Retrieval Augmented Generation (VisDoMBench)," arXiv preprint arXiv:2412.10704, 2024. DOI: https://doi.org/10.18653/v1/2025.naacl-long.310
[21] S. Amirshahi, et al., “Evaluating the Robustness of Retrieval Augmented Generation to Adversarial Evidence in the Health Domain,” arXiv preprint arXiv:2509.03787, 2025.
[22] Y. Song and S. Ermon, "Generative modeling by estimating gradients of the data distribution," in NeurIPS, vol. 32, 2019, p. 11895.
[23] J. Ho, A. Jain, and P. Abbeel, "Denoising diffusion probabilistic models," in NeurIPS, vol. 33, 2020, p. 6840.
[24] J. Song, C. Meng, and S. Ermon, "Denoising diffusion implicit models," in ICLR, vol. 9, 2021, p. 1.
[25] D.P. Kingma, T. Salimans, B. Poole, et al., "Variational diffusion models," in NeurIPS, vol. 34, 2021, p. 21696.
[26] M. Li, S. Miao, and P. Li, "Simple is effective: The roles of graphs and LLMs in KG-based RAG," in ICLR, vol. 13, 2025, p. 1.
[27] V.N. Rao, S. Choudhary, A. Deshpande, et al., "RAVEN: Multitask retrieval augmented vision-language learning," arXiv preprint arXiv:2406.19150, 2024.
[28] M. Mortaheb, M.A. Khojastepour, S.T. Chakradhar, et al., "RAG-Check: Evaluating multimodal retrieval augmented generation performance," arXiv preprint arXiv:2501.03995, 2025.
[29] Z. Hu, A. Iscen, C. Sun, Z. Wang, K. W. Chang, Y. Sun, C. Schmid, D. A. Ross, and A. Fathi, “REVEAL: Retrieval Augmented Visual Language Pre Training with Multi Source Multimodal Knowledge Memory,” in Proc. IEEE/CVF Conf. Comp. Vis. Patt. Recog. (CVPR), 2023, pp. 23369–23379. DOI: https://doi.org/10.1109/CVPR52729.2023.02238
[30] Y.W. Chu, K. Zhang, C. Malon, et al., "Reducing hallucinations of medical MLLMs with visual RAG," arXiv preprint arXiv:2502.15040, 2025.
[31] P. Jiang, S. Ouyang, Y. Jiao, M. Zhong, R. Tian, and J. Han, “A Survey on Retrieval And Structuring Augmented Generation with Large Language Models,” arXiv preprint arXiv:2509.10697, 2025. DOI: https://doi.org/10.1145/3711896.3736557
[32] Y. Chen, H. Hu, Y. Luan, H. Sun, S. Changpinyo, A. Ritter, and M. W. Chang, “Can Pre-trained Vision and Language Models Answer Visual Information Seeking Questions?,” arXiv preprint arXiv:2302.11713, 2023. DOI: https://doi.org/10.18653/v1/2023.emnlp-main.925
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Computational Discovery and Intelligent Systems (CDIS)

This work is licensed under a Creative Commons Attribution 4.0 International License.
Computational Discovery and Intelligent Systems (CDIS) content is published under a Creative Commons Attribution License (CCBY). This means that content is freely available to all readers upon publication, and content is published as soon as production is complete.
Computational Discovery and Intelligent Systems (CDIS) seeks to publish the most influential papers that will significantly advance scientific understanding. Selected articles must present new and widely significant data, syntheses, or concepts. They should merit recognition by the wider scientific community and the general public through publication in a reputable scientific journal.










