
A Comparative Analysis of Contrastive and Generative Vision-Language Models for Zero-Shot Behavior Recognition in Surveillance Videos
DOI:
https://doi.org/10.66279/vcth9h10Keywords:
Vision–Language Models, Zero-Shot Learning, Behavior Recognition, Surveillance VideosAbstract
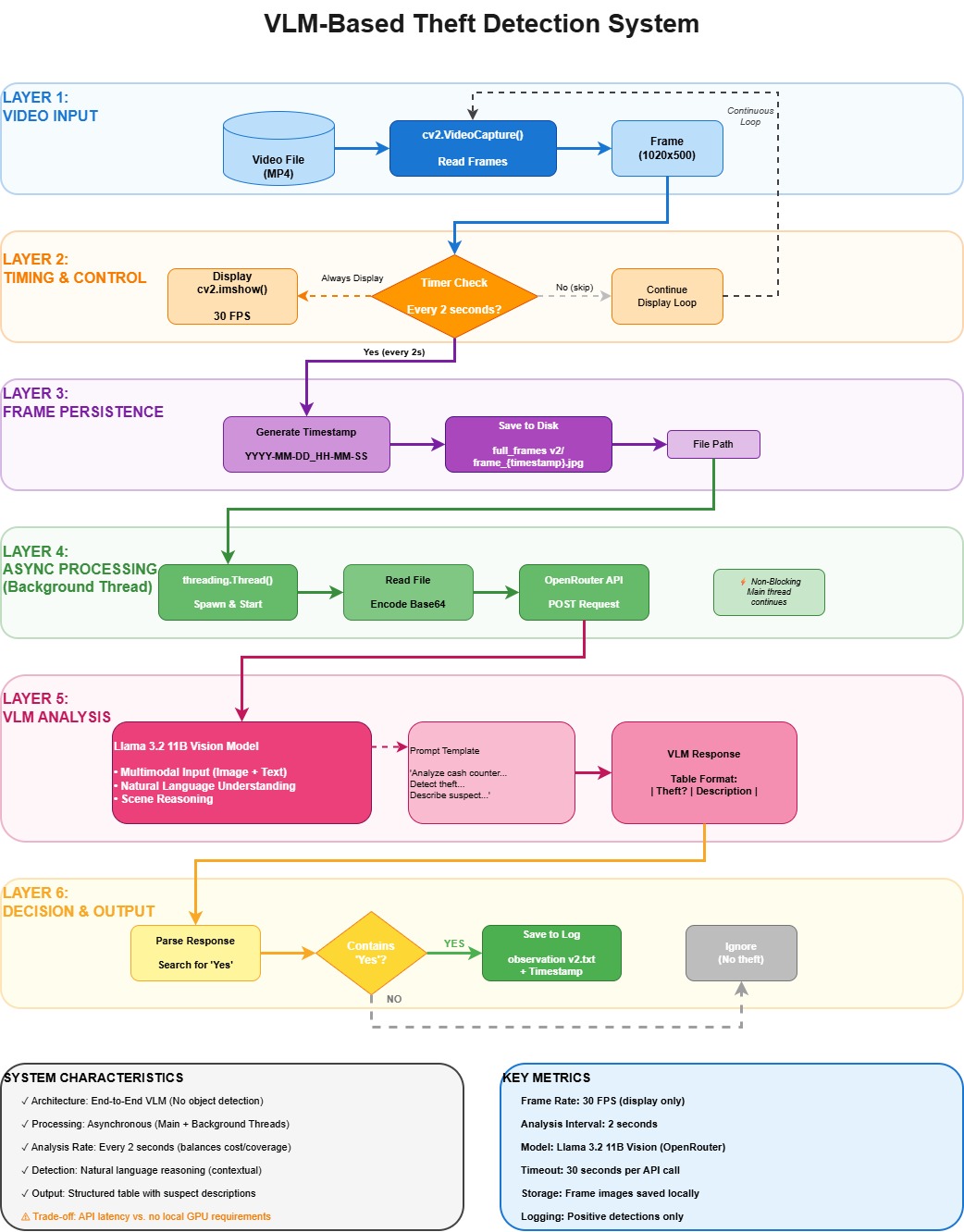
Vision-language models (VLMs) have recently demonstrated strong zero-shot capability for object recognition and scene classification, yet their suitability for modeling covert human behaviors, such as theft, remains largely unexamined. This paper presents a case study comparing two zero-shot VLM paradigms for cashier theft detection in surveillance footage: a contrastive embedding model (CLIP) and a generative vision-language model (a Llama-3.2-11B-Vision-based pipeline operating in the BLIP/BLIP-2 family of generative architectures). On a set of real cashier-counter recordings, the contrastive model produced near-tied confidence scores between theft and normal-activity prompts (theft confidence 0.504, normal-activity confidence 0.496), indicating weak discriminative margin when intent and temporal context are required. The generative pipeline, in contrast, produced confident and structured binary outcomes (theft confidence 1.000, normal-activity confidence 0.000) accompanied by interpretable natural-language descriptions of the suspect and the event. These results, while drawn from a small, non-benchmarked sample rather than a large annotated corpus, suggest that contrastive similarity scoring is better suited to fast object-level screening, whereas generative reasoning is better suited to behavior-level interpretation. A hybrid pipeline that couples a fast contrastive pre-filter with a generative reasoning stage is proposed as a practical direction for zero-shot surveillance systems that require both efficiency and interpretability
Downloads
References
[1] R. Chalapathy and S. Chawla, “Deep learning for anomaly detection: A survey,” arXiv preprint arXiv:1901.03407, 2019.
[2] W. Liu, W. Luo, D. Lian, and S. Gao, “Future frame prediction for anomaly detection–a new baseline,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6536–6545, 2018. DOI: https://doi.org/10.1109/CVPR.2018.00684
[3] W. Sultani, C. Chen, and M. Shah, “Real-world anomaly detection in surveillance videos,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6479–6488, 2018. DOI: https://doi.org/10.1109/CVPR.2018.00678
[4] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning, pp. 8748–8763, PmLR, 2021.
[5] J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in International conference on machine learning, pp. 12888–12900, PMLR, 2022.
[6] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International conference on machine learning, pp. 19730–19742, PMLR, 2023.
[7] P. Wu, X. Zhou, G. Pang, L. Zhou, Q. Yan, P. Wang, and Y. Zhang, “Vadclip: Adapting vision-language models for weakly supervised video anomaly detection,” in Proceedings of the AAAI conference on artificial intelligence, vol. 38, pp. 6074–6082, 2024. DOI: https://doi.org/10.1609/aaai.v38i6.28423
[8] L. Zanella, B. Liberatori, W. Menapace, F. Poiesi, Y. Wang, and E. Ricci, “Delving into clip latent space for video anomaly recognition,” Computer Vision and Image Understanding, vol. 249, p. 104163, 2024. DOI: https://doi.org/10.1016/j.cviu.2024.104163
[9] H. K. Joo, K. Vo, K. Yamazaki, and N. Le, “Clip-tsa: Clip-assisted temporal self-attention for weakly-supervised video anomaly detection,” in 2023 IEEE International Conference on Image Processing (ICIP), pp. 3230–3234, IEEE, 2023. DOI: https://doi.org/10.1109/ICIP49359.2023.10222289
[10] J. Lu, D. Batra, D. Parikh, and S. Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,” Advances in neural information processing systems, vol. 32, 2019.
[11] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision-language models,” International journal of computer vision, vol. 130, no. 9, pp. 2337–2348, 2022. DOI: https://doi.org/10.1007/s11263-022-01653-1
[12] Z. Weng, X. Yang, A. Li, Z. Wu, and Y.-G. Jiang, “Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization,” in International conference on machine learning, pp. 36978–36989, PMLR, 2023.
[13] S. Ahmad, S. Chanda, and Y. S. Rawat, “Ez-clip: Efficient zeroshot video action recognition,” arXiv preprint arXiv:2312.08010, 2023.
[14] W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 49250–49267, 2023. DOI: https://doi.org/10.52202/075280-2142
[15] L. Zanella, W. Menapace, M. Mancini, Y. Wang, and E. Ricci, “Harnessing large language models for training-free video anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18527–18536, 2024. DOI: https://doi.org/10.1109/CVPR52733.2024.01753
[16] Y. Yang, K. Lee, B. Dariush, Y. Cao, and S.-Y. Lo, “Follow the rules: reasoning for video anomaly detection with large language models,” in European Conference on Computer Vision, pp. 304–322, Springer, 2024. DOI: https://doi.org/10.1007/978-3-031-73004-7_18
[17] H. Lv and Q. Sun, “Video anomaly detection and explanation via large language models,” arXiv preprint arXiv:2401.05702, 2024.
[18] J. Jeong, Y. Zou, T. Kim, D. Zhang, A. Ravichandran, and O. Dabeer, “Winclip: Zero-/few-shot anomaly classification and segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 19606–19616, 2023. DOI: https://doi.org/10.1109/CVPR52729.2023.01878
[19] Y. Kong and Y. Fu, “Human action recognition and prediction: A survey,” International Journal of Computer Vision, vol. 130, no. 5, pp. 1366–1401, 2022. DOI: https://doi.org/10.1007/s11263-022-01594-9
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2026 Engineering Systems and Intelligent Technologies (ESIT)

This work is licensed under a Creative Commons Attribution 4.0 International License.
Engineering Systems and Intelligent Technologies (ESIT) content is published under a Creative Commons Attribution License (CCBY). This means that content is freely available to all readers upon publication, and content is published as soon as production is complete.
Engineering Systems and Intelligent Technologies (ESIT) seeks to publish the most influential papers that will significantly advance scientific understanding. Selected articles must present new and widely significant data, syntheses, or concepts. They should merit recognition by the wider scientific community and the general public through publication in a reputable scientific journal.










