
Intelligent Arabic News Classification Systems Using AraBERT Transformer for Digital Media Engineering
DOI:
https://doi.org/10.66279/x90c8d75Keywords:
Arabic News Classification, AraBERT, Transformer Models, SANAD DatasetAbstract
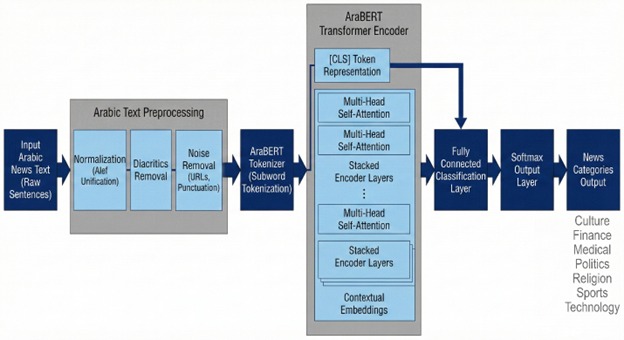
The rapid expansion of Arabic digital news has created a pressing need for accurate and scalable automatic news categorization. Arabic natural language processing remains challenging because of the morphological richness of the language, its complex syntax, the prevalence of dialectal variation, and the near-universal absence of diacritics in online text. This paper proposes a transformer-based framework for Arabic news classification centered on fine-tuned AraBERT, a bidirectional encoder pre-trained exclusively on large-scale Arabic corpora. The framework incorporates Arabic-specific text preprocessing, subword tokenization via the AraBERT tokenizer, and a single fully connected softmax classifier appended to the contextual [CLS] representation. Experiments are conducted on the SANAD benchmark dataset, which contains approximately 194,797 Modern Standard Arabic news articles distributed across seven topical categories. The proposed model achieves an accuracy of 98.4%, a macro-averaged precision of 99.1%, a macro-averaged recall of 99.8%, and a macro-averaged F1-score of 99.0%, outperforming fine-tuned multilingual baselines mBERT and XLM-R by substantial margins. Detailed error analysis via confusion matrix and per-class classification reports confirms strong generalization across all categories, with only minor confusion between thematically adjacent domains such as Politics and Finance. The results validate that Arabic-focused pre-training is decisive for high-quality Arabic news categorization and establish a reproducible, scalable pipeline for future research.
Downloads
References
[1] O. Einea, A. Elnagar, and R. Al Debsi, “Sanad: Single-label arabic news articles dataset for automatic text categorization,” Data in brief, vol. 25, DOI: https://doi.org/10.1016/j.dib.2019.104076
p. 104076, 2019.
[2] M. Al-Ayyoub, A. A. Khamaiseh, Y. Jararweh, and M. N. Al-Kabi, “A comprehensive survey of arabic sentiment analysis,” Information processing & management, vol. 56, no. 2, pp. 320–342, 2019. DOI: https://doi.org/10.1016/j.ipm.2018.07.006
[3] W. Antoun, F. Baly, and H. Hajj, “Arabert: Transformer-based model for arabic language understanding,” in Proceedings of the 4th workshop on open-source arabic corpora and processing tools, with a shared task on offensive language detection, pp. 9–15, 2020.
[4] M. Abdul-Mageed, A. Elmadany, et al., “Arbert & marbert: Deep bidirectional transformers for arabic,” in Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pp. 7088–7105, 2021. DOI: https://doi.org/10.18653/v1/2021.acl-long.551
[5] F. Sebastiani, “Machine learning in automated text categorization,” ACM computing surveys (CSUR), vol. 34, no. 1, pp. 1–47, 2002. DOI: https://doi.org/10.1145/505282.505283
[6] Y. Kim, “Convolutional neural networks for sentence classification,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1746–1751, 2014. DOI: https://doi.org/10.3115/v1/D14-1181
[7] S. Lai, L. Xu, K. Liu, and J. Zhao, “Recurrent convolutional neural networks for text classification,” in Proceedings of the AAAI conference on artificial intelligence, vol. 29, 2015. DOI: https://doi.org/10.1609/aaai.v29i1.9513
[8] E. Alnagi, R. Ghnemat, and Q. Abu Al-Haija, “Boosting arabic text classification using hybrid deep learning approach,” Discover Applied Sciences, vol. 7, no. 6, p. 540, 2025. DOI: https://doi.org/10.1007/s42452-025-07025-x
[9] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
[10] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186, 2019. DOI: https://doi.org/10.18653/v1/N19-1423
[11] A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, and V. Stoyanov, “Unsupervised cross-lingual representation learning at scale,” in Proceedings of the 58th annual meeting of the association for computational linguistics, pp. 8440–8451, 2020. DOI: https://doi.org/10.18653/v1/2020.acl-main.747
[12] I. Jamaleddyn, R. El Ayachi, and M. Biniz, “Novel multi-channel deep learning model for arabic news classification.,” Jordanian Journal of Computers & Information Technology, vol. 10, no. 4, p. 453, 2024. DOI: https://doi.org/10.5455/jjcit.71-1720086134
[13] R. Alqahtani and H. Abdelhafez, “Arabic text classification using machine learning and deep learning algorithms,” IAES International Journal of Artificial Intelligence (IJ-AI), vol. 14, p. 5201, 12 2025. DOI: https://doi.org/10.11591/ijai.v14.i6.pp5201-5217
[14] R. Abou Khachfeh, I. El Kabani, and Z. Osman, “An enhanced hybrid bert-bilstm learning model for arabic news classification,” in 2025 International Conference on Machine Intelligence and Smart Innovation (ICMISI), pp. 201–206, IEEE, 2025. DOI: https://doi.org/10.1109/ICMISI65108.2025.11115581
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2026 Engineering Systems and Intelligent Technologies (ESIT)

This work is licensed under a Creative Commons Attribution 4.0 International License.
Engineering Systems and Intelligent Technologies (ESIT) content is published under a Creative Commons Attribution License (CCBY). This means that content is freely available to all readers upon publication, and content is published as soon as production is complete.
Engineering Systems and Intelligent Technologies (ESIT) seeks to publish the most influential papers that will significantly advance scientific understanding. Selected articles must present new and widely significant data, syntheses, or concepts. They should merit recognition by the wider scientific community and the general public through publication in a reputable scientific journal.










